LUGS - Vorträge: Coda vom 11.3.1999
|
Am 11. März 1999 hat Beat Rubischon einen Vortrag über Coda gehalten. Ich schreibe hier eine kurze Zusammenfassung darüber. Weder war der Vortrag eine Konfigurations- oder Installationsanleitung, noch soll dieser Artikel das nachholen. Ich will einfach einen kleinen Überblick über die Funktionalität, die Vor- und Nachteile von Coda geben. Idee und HerkunftCoda kommt ursprünglich aus der Welt der Gross-Systeme von IBM und ist dort aus dem AFS (Andrew File System) entstanden. Das merkt man dem System auch an verschiedenen Stellen an. Alles Wissenswerte über Coda (HOWTO, Installationsanleitung et al.) ist von der Coda-Homepage erhältlich. Die Idee bei Coda ist, dass nicht nur ein Server die Daten zur Verfügung stellt, sondern ein ganzes Rudel von Servern. Der Client kann dann auswählen, welchen Server er benutzen möchte. Als Kriterium werden da zum Beispiel die Erreichbarkeit oder die Antwortzeit herangezogen. Die Server stehen dabei untereinander auch in Verbindung und sorgen für einen ständigen Abgleich der Daten, sodass auf allen Servern die aktuellen Daten vorhanden sind. Die Verbindungen zwischen den Servern und den Clients müssen nicht dauernd vorhanden sein, das System funktioniert trotzdem. Dazu hat jeder Client einen eigenen Cache auf seiner lokalen Festplatte. Aufbau auf Server-Seite
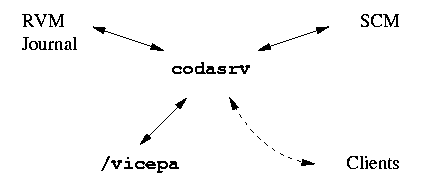
Die Daten, die auf dem Coda-Server liegen, werden unter /vicepa gespeichert. Und zwar nicht so wie bei NFS als normale Files und Verzeichnisse, sondern eher wie bei Squid in einer eigenen Verzeichnis-Struktur. Dazu gehört natürlich noch die Datenbank RVM (Recoverable Virtual Memory) mit den Informationen, welches File wo in der Verzeichnis-Struktur unter /vicepa zu finden ist. Die Grösse des RVM muss 4% des gesamten Platzes des Coda-Servers betragen und das RVM wird dann in den Speicher gemapt. Das heisst für viel Platz auf dem Server braucht es auch viel Platz im Hauptspeicher (am besten physikalisch). Zusätzlich dazu gibt es noch ein Journal, in dem alle Vorgänge in Coda aufgezeichnet werden. Dadurch wird das ganze System bei Abstürzen viel weniger beschädigt (meist sogar gar nicht). Auf dem Server läuft der codasrv-Prozess, der die Kommunikation mit den Clients erledigt. Er ist zuständig für den Daten-Versand und die Authentifikation der User auf den Clients. Diese müssen sich sowohl auf Ihrer Workstation als auch beim Coda-Server anmelden. So eine Anmeldung bleibt 24 Stunden gültig. An den Authentifikations-Daten darf übrigens nur ein Server (System Controll Machine SCM) Änderungen vornehmen. Wie schon erwähnt, können mehrere Coda-Server die gleichen Daten haben und den Clients anbieten. Das muss aber nichts so sein. Es können auch verschiedene Coda-Server verschiedene Daten verwalten und anbieten. Für einen Client ist es dann egal, zu welchem Server er Verbindung aufnimmt, er sieht immer alle zugänglichen Daten in des "`Server-Clusters"'. In der Terminologie von Coda: die Server einer Zelle verwalten Volumes, die dann in das /coda-Verzeichnis gemountet werden. Jeder Server muss auch das Root-Volume verwalten. Ein kleines Beispiel:
home und stuff sind also nicht auf allen Servern vorhanden. Der Client sieht allerdings in seinem /coda-Verzeichnis folgendes Bild.
Und das unabhängig vom Server, zu welchem er Verbindung aufgenommen hat. Aufbau auf Client-Seite
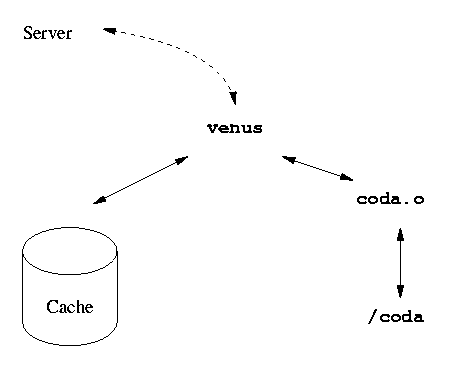
Auf dem Client läuft der venus-Prozess, der die Schnittstelle zwischen Cache, Server und dem Coda-Modul im Kernel bildet. Dieses Modul ist seit 2.1.x im Kernel dabei. Es sorgt für die Verbindung zwischen dem Verzeichnis /coda auf den Clients und dem venus-Prozess. Wenn man Verbindung zu einem Coda-Server aufnimmt, dann kann man dessen Verzeichnisse nicht wie bei NFS an beliebige Stellen mounten, sondern sie erscheinen unter /coda. Der Cache besteht aus einer Datei, deren Grösse festgelegt werden kann. Die Verbindung zum Server und die Verbindung unter den Server basiert auf UDP und ist also "`verbindungslos"' (so wie bei NFS -- im Gegensatz zu TCP zum Beispiel bei Telnet). Vor- und NachteileZuerst die Vorteile:
Dann die Nachteile:
Zusammenfassung des Vortrags durch Philipp Frauenfelder |